For thousands of years humans have understand the power of the written word. As a result great care was given to preserving books and other written documents. But in the digital age we live in there is a desperate need to be able to sift through the ever growing volumes of generated text. Fortunately for us new information technologies are available to us average folk that enable us to mine digital text.
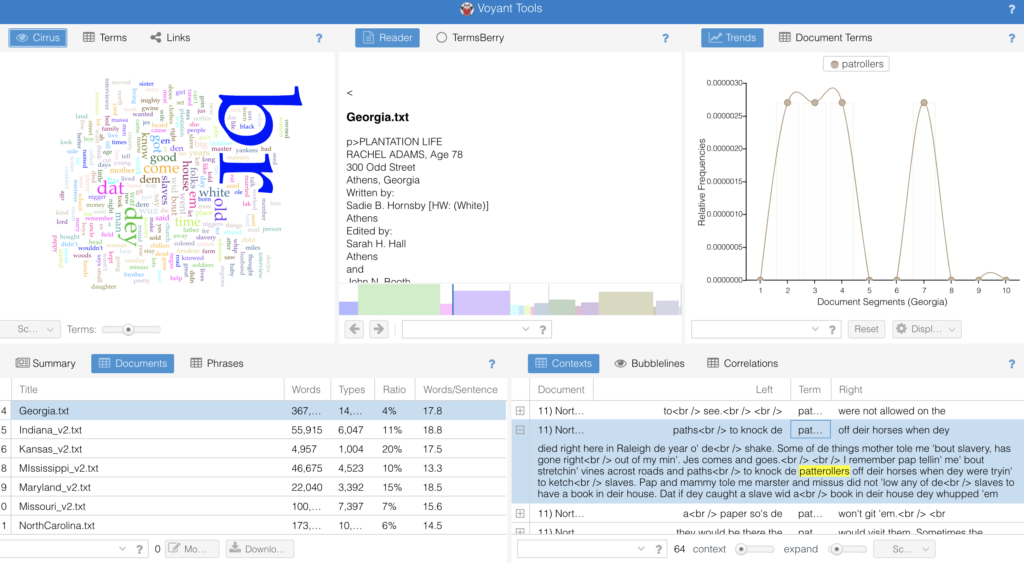
Recently I was able to test drive an application called “Voyant”. On their website they describe themselves as a web-based reading and analysis environment for digital text. For us digital historians Voyant is an inexpensive was to explore the world of text mining. As with all things digital, not everything is as simple as it looks. Voyant is no different. In text mining projects involving large corpus there is both a pro and con to how to proceed. What makes Voyant incredibly powerful is its intuitive user interface and visual displays. Unfortunately the user needs to understand the basics of text mining. For example, there needs to be some familiarity with concepts such as vocabulary density, frequency, and distinctiveness. Also, mining operation has to distinguish between the overall findings for the corpus or collection, versus the unique findings that can be found in an individual document.

For my class we were assigned to use a rather interesting text collection called the “WPA Slave Narratives“. It was a Works Progress Administration project from the Great Depression, where writers set out to gather and capture the stories of formerly enslaved people. As a historical collection it is a fascinating look back in time. The writers collected testimony from 2.300 people across 17 states. it includes over 9,500 pages. In the past trying to conduct a text mining project of this size would have been insurmountable. But the moment the original collection was scanned and digitized the narratives became a valuable resource. A quick search online revealed that dozens of books have been written using the collection.

The slave narratives was an excellent case study to try to work through how one can leverage text mining. The nature of the original project back in the 1930s never intended to be “mined” digitally. But what I learned is that in the writer’s attempt to record the narratives as authentically as possible, they also captured the interviewees variances of local dialect, poor grammar, and faded memories. As a result. the entire corpus reflects a unique challenge to sort through digitally today.
The value of using an application such as Voyant can not be minimized. It really helped identify the variations in word usage through the text cloud, but it was the other available functionalities, ie: reading, trends, context, and summary tools that provided a way to identify thematically similar information across the corpus. I highly recommend getting started using Voyant, but be prepared to navigate through a new way of thinking about how words are related, and how they need to be extracted to gain better insight or value.